









脱カン・コツ・ドキョウ!需要予測業務は、AI モデルを利用して、データドリブンに関係者間で意志決定を

需要予測を行う AI モデルを構築することで実現したい世界は?
本コラムは中編
の続きとなります。
前回のコラムでは、AI での需要予測を実現したいと考えられているお客様の多くが、「実担当者が勘と経験(カンコツ)をベースに実施している予測を、属人化をなくすとともに精度を向上させたい」と思われている方々であると、お話しをいたしました。
では、この状態は AI の需要予測モデルを作れば実現されるでしょうか?
以下に、需要予測を実業務で行われているお客様で、よくある場面をイメージ化します。
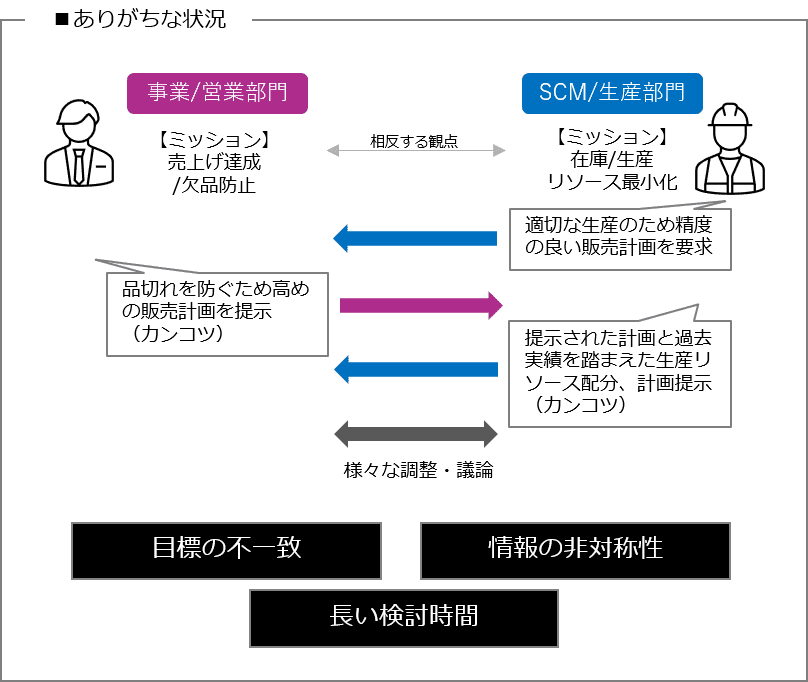
ある製品の需要予測を業務として行っているとしましょう。
その業務には通常、その製品をお客様に届ける事業/営業部門の方と、その製品を生産する SCM/生産部門の方が関わっています。
事業/営業部門の方のミッションは、売上げの最大化です。そのためには、お客様が欲しいと言うときにできるだけ早く商品を提供し、お客様が欲しいときに商品がないと言う欠品を防止させたいわけです。
SCM/生産部門の方のミッションは、在庫と生産リソースの最小化です。
極端な話、あるお客様が欲しいときに商品の提供が遅れたとしても、もし遅れないように在庫をたくさん持ったり、生産能力をおさえて、多くのコストがかかったりすることを防止できれば、その方が良いわけです。
勿論、会社の売上げと利益最大化のためにお互いの状況はわかってはいるものの、お互いのミッションの違いから、様々な調整や議論が発生します。
また、会社によっては、実際の過去時点の生産数、販売数、在庫数等が IT の仕組みとして見える化できていない場合もあります。
その場合、事業/営業部門の方は実際売れた数は把握しているが、SCM/生産部門の方が把握している在庫量や、生産能力は把握できていなかったりなど、情報の非対称性が発生しているため、その議論はより長い時間が必要になったり、カンコツに頼ることになります。
実際カンコツで決めた生産計画、販売計画で進めて、実際にうまく行かなかったとしても、そのカンコツ予測の妥当性を振り返る余裕もないため、ふりかえることなく次の議論に入っていくというような実運用の企業様もいらっしゃいます。
特に、そのような場面になりがちなお客様に、AI による需要予測を利用し、データドリブンに需要予測業務を進めることをおすすめします。そのイメージは以下となります。
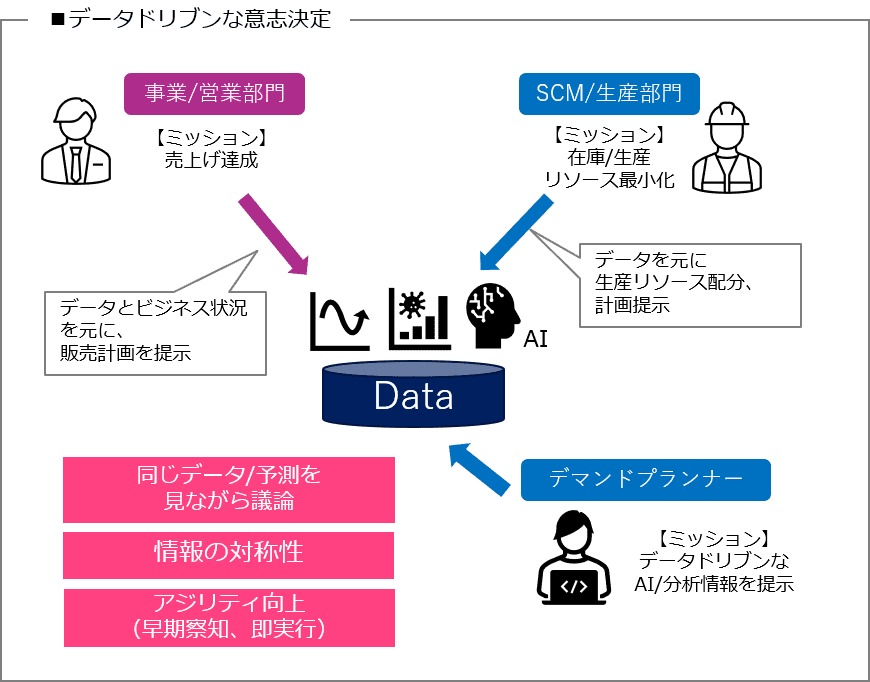
AI のモデル構築/改善を行うご担当の方をデマンドプランナーと記載しています。
まず、仕組みとしてデマンドプランナーが、AI 需要予測結果を、過去の実績データも合わせて可視化を行います。
それらデータを中心に、それぞれ事業/営業部門、SCM/生産部門の方々が共に、議論する業務の流れにしていきます。
さらに、“ありがちな状況”で課題だった、情報の非対称性を解消することで、カンコツから入らず、データドリブンに需要予測を行うことが可能となります。
ここでの一番のポイントは、ミッションが相反する事業/営業部門の方と、SCM/生産部門の方が、お互い対立するのではなく、1 つの事実である共通のデータを見ながら、ある意味第三者的な意見となる AI を中心として、お互いに議論する場ができあがる所です。
このように、データ/AI を中心にすることで、より正確な需要予測だけでなく、意志決定のスピード UP、アジリティ向上が実現できます。
カンコツ需要予測からの脱却
結局、カンコツに頼らない需要予測を実現するためにはどうしたら良いのでしょうか?それは、以下 3 つの観点を総合的に考え、トライアル&エラーを繰り返しながら進めて行くことです。
- データ
- 仕組み
- AI/データ分析ノウハウ
以下、それぞれイメージ図と合わせて説明していきます。
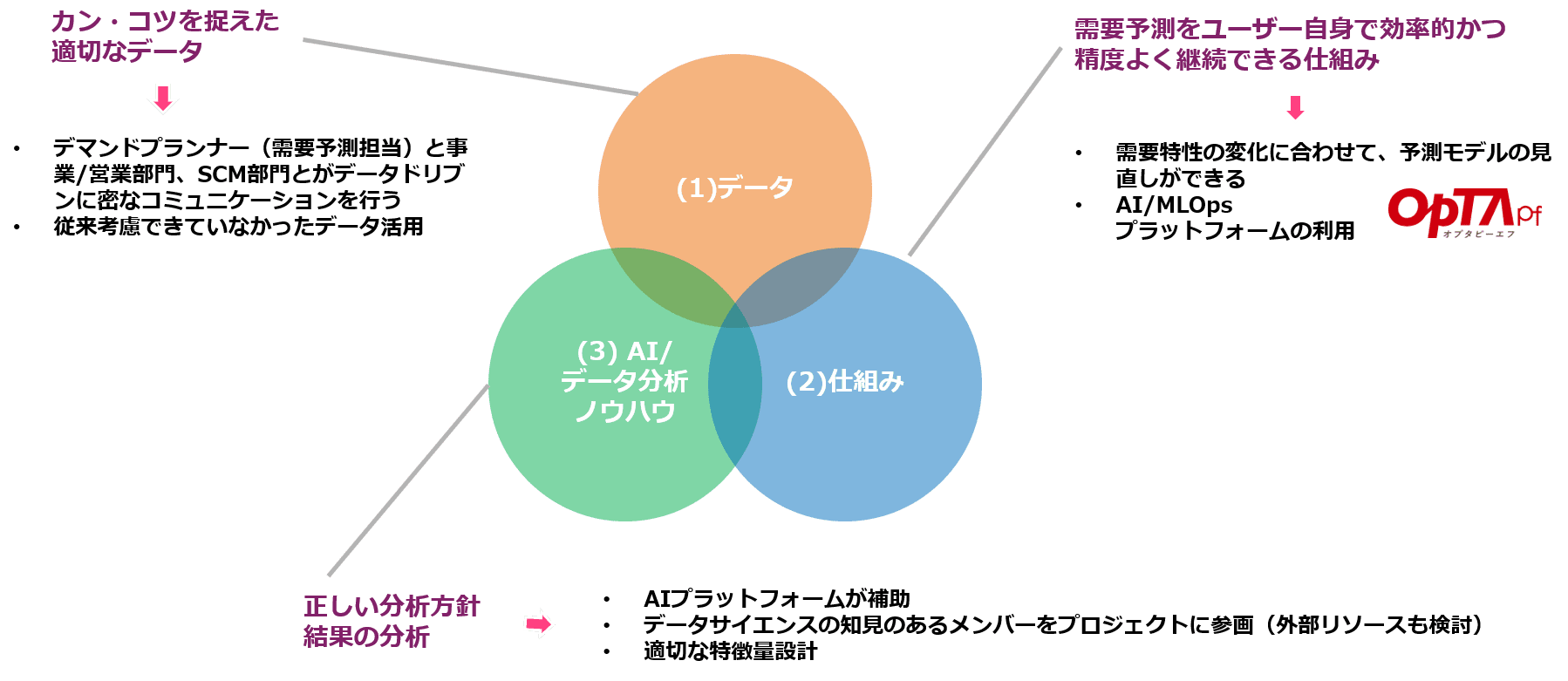
(1)のデータに関してです。カンコツを捉まえた適切なデータをこれからも集めて利用していくことが重要です。
AI だからいろいろなデータを適当に学習させておけば良いのでしょというお話しをお客様から言われたことはありますが、それは正しくありません。
AI に学習させるデータは、需要予測に寄与するデータでなければ意味がありません。
それでは、需要予測に寄与するデータかどうかはどうすればわかるでしょうか?もちろん、様々なデータを学習データとして準備し、AI モデルを作成し、その解釈性や説明性を見ることで“需要予測に寄与するデータ”が何かはわかります。
しかし、そのやってみるコストやスピードを考慮すると、今までのカンコツで使ってきたデータやその見方などが、まさに“需要予測に寄与するデータ”である場合が多いためです。
例えば、この予測には、この別の情報がこう変わるとこう変わりやすいんだよとか、この商品は、こういう特徴があるから、こういう部分も踏まえて考えているんだよ、と言った現場のカンコツを、ちゃんとデータ化し、AI に教えてあげることが一番の近道です。
データに関しては様々な観点があり、本コラムでは言い尽くせないですが、もう一つお話しするとすれば、まさに AI をなぜ使うか?という部分にも繋がることです。
それは、AI を利用することで、人が判断するには、不可能なデータ量(特にデータ項目数)を需要予測の判定に利用できることです。つまり。多くの項目の時系列データを考慮することで、より良い需要予測が実現できます。
次に、(2)の仕組みに関してです。需要予測 AI のモデル構築に関して最も重要なことは何でしょうか?
1 番は、構築することではなく、運用を継続していくことです。運用していくとは、具体的には、最新のデータを準備し、最新のデータで AI モデルの再学習を継続し、世の中の状況に合わせて AI モデルを改善し続けるということです。
世の中の状況というのは、以下のような外的要因や、内的要因などがあります。
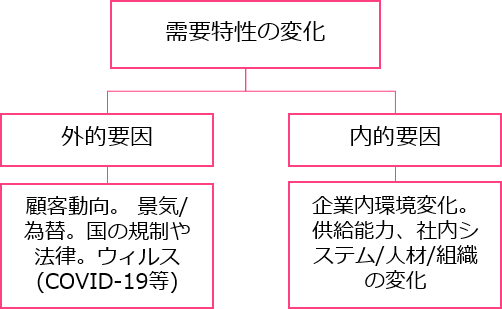
これら様々な変化を、(1)のデータに継続的に反映していき、そのデータを利用して、AI モデルの再学習を継続実施して行くことで、AI モデルの精度低下を防止し、精度向上に繋げていく必要があります。
このような AI 運用を実現するための仕組みは MLOps(エムエルオプツ)と呼ばれています。需要予測 AI には、多くの時間やコスト、技術力を有する事の無い、この MLOps に対応した AI プラットフォームが求められます。
最後に、(3)の AI/データ分析ノウハウに関してです。(2)でお話しした MLOps 対応の AI プラットフォームとして、例えば弊社が提供している OpTApf/オプタピーエフを利用すると、MLOps 部分だけで無く、コーディングや AI モデルの選定など、AI モデル構築の技術的なハードルをかなり下げ、作業の自動化も進めることが可能です。
しかし、それを使えばデータサイエンス的な知見が全く必要ないかというと、そうではないです。
特に、実際のデータに対して、現場のカンコツ部分(このデータはこういう風に見ている)とか、そもそも統計的な計算を実施したデータ作成の部分、“どういう学習データにするか“という部分には、データサイエンスのノウハウが追加されると、より良い結果に繋がりやすくなります(より良い AI モデルにするためのデータ作成を、特徴量作成と言ったりします)。
つまり、より高い精度の需要予測を行いたいという場合は、データサイエンスの知見のあるメンバーをプロジェクトに参画することが重要となります。
もし、社内で知見のある方がいらっしゃらない場合は、外部ベンダーの力を借りるという方法もあると思っております。
もちろん我々 AITC も日々単に OpTApf 等の環境を提供するだけではなく、お客様の需要予測に AI を適用し、継続して運用できるよう日々ご支援しております。
まとめ
以下、“需要予測は AI で行う時代へ”と題して 3 部構成でお話しさせていただきました。
前編、中編よりも、後編が長くなってしまいましたが、一番伝えたかったのは、“需要予測 AI を業務に適用することで、組織として継続可能な、対立ではなく協調した需要予測業務を目指しませんか?”という内容でした。
AITC はお客様の AI/データ活用を実運用するご支援を行っていますので、いつでもご相談ください。
執筆
AITC センター長
深谷 勇次
