









脱カン・コツ・ドキョウ!需要予測業務は、AI モデルを利用して、データドリブンに関係者間で意志決定を

本コラムは前編
の続きとなります。需要予測を実施する上で重要となる視点に関してお話ししていきたいと思います。
需要予測を実施する上で重要となる視点 1:業界、業務要件に応じた需要予測
「何の需要予測をしたいのか?」、「その結果をどのような目的で利用するのか?」という目的の明確化については、これまでに掲載した他のコラムでその重要性を説明してきました。
同じ受注量の需要予測と言っても、業種業態によって業務要件は異なるため、業務要件に応じた需要予測が必要です。
業種、業態によって様々な切り口は考えられますが、以下は価格と定番か新製品かを切り口としたイメージになります。
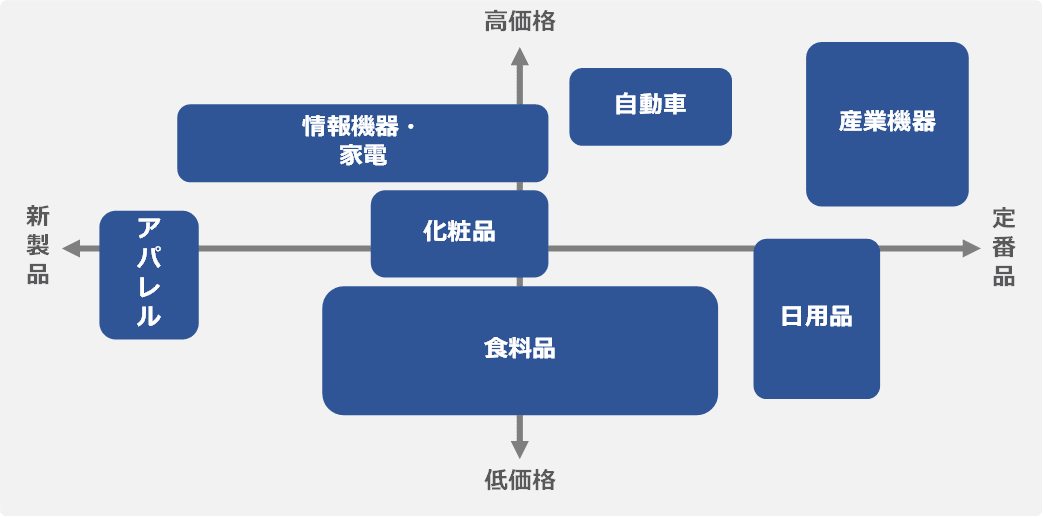
そもそも同じ商品がほとんどないようなアパレル製品や食品などは、何年後も同じ製品があるような産業機器や日用品などとは、実現したい需要予測、考えるべきことは異なります。
定番品になるほど、短期的な予想は容易であり、中長期的な予測がよりビジネス価値として重要となってきます。
また、AI を利用するとなると、どのようなデータで学習させるかが最も重要です。そうなると、過去データがある定番品と、直接的な過去データがない新製品とでは、技術的な観点も大きく変わる場合があります。
需要予測を実施する上で重要となる視点 2:予測誤差の分析
時間が経てば、世の中の状況は変わります。AI に学習させた過去データですべて説明がつく世界は存在しないため、直近の学習データ増やし、定期的に AI モデルを更新していくことが、AI による需要予測では必要です。
再学習を継続しながら運用していったとしても、予測精度が低下したり、誤差が大きくなったりすることはありえます。そこで重要となってくるのは、予測精度が低下した場合に、なぜ誤差が生じたかを分析することです。例えば、以下のような新型コロナウイルスの影響で、予測が外れた場合などです。
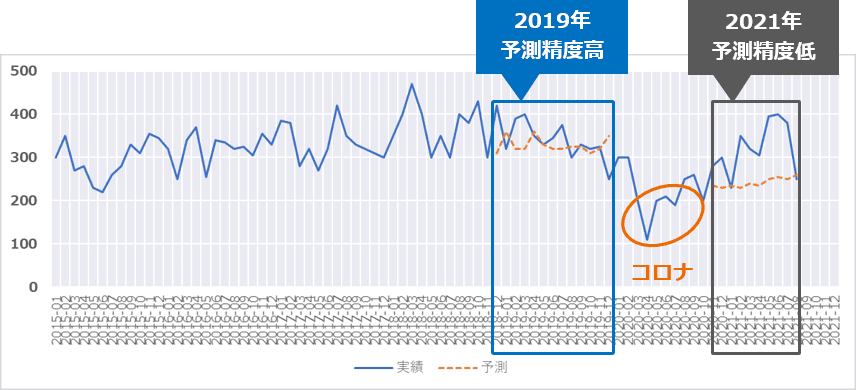
誤差分析結果を元に予測 AI を改善していくことで、精度や環境変化対応性を向上させていくことが重要です。
AI は予測の理由がわからないのでは?という議論は主にニューラルネットワークを利用した AI モデルの際に聞かれることがあります。しかし、昨今開発された SHAP や LIME、Anchorsと言った技術を用いることや、そもそも解釈性が高いランダムフォレストのような機械学習モデルを利用することで、AI モデルが説明性と解釈性を提示し、なぜその AI は予測を外しているのか、当たっているのかを理解することが可能です。
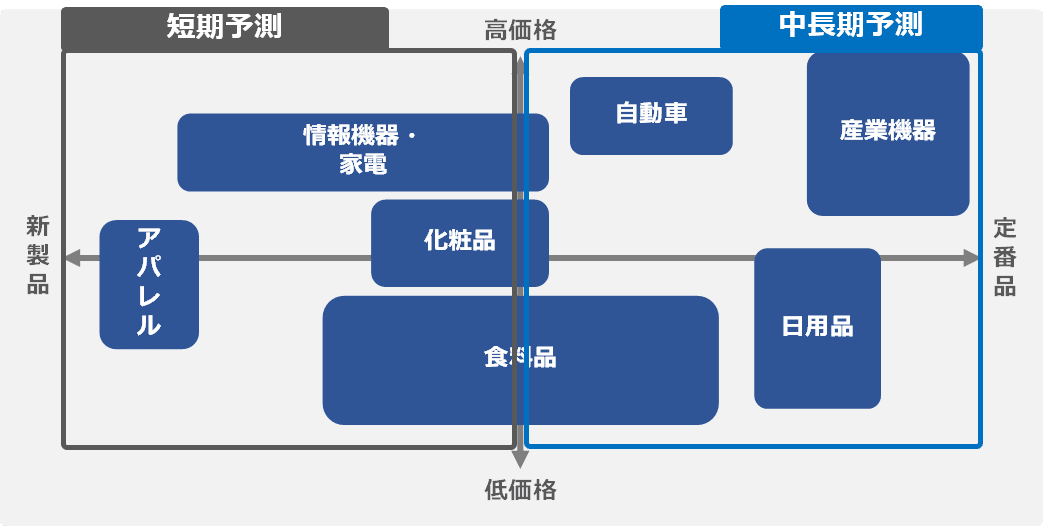
需要予測を、短期と中長期予測に分類した場合、特に中長期予測には AI を利用する
需要予測を実施する上で重要となる視点 1:業界、業務要件に応じた需要予測の所で説明しましたが、短期と中長期予測という 2 つの視点で需要予測を分けると以下のように表すことができます。
短期予測を典型的な例で説明すると「一般的な小売業で実施してる SKU(Stock Keeping Unit)単位の予測」ということができ、イメージは以下のようになります。
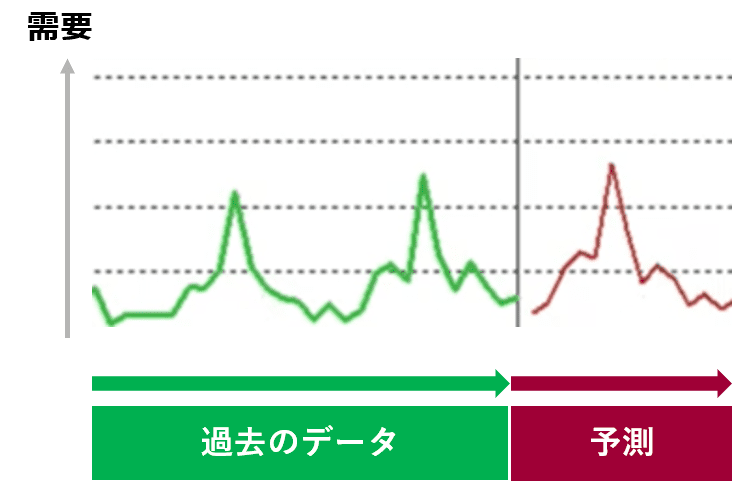
このような予測は、多品種であり、過去のデータがほとんどないような新商品も多かったりします。
その場合、単純な移動平均法のような仕組みや、ERP(Enterprise Resources Planning)に内包されているような、ウィンターズ法や SARIMA モデルと言った方法を利用することが一般的だったりします。
なぜならば、ほぼ過去の需要という目的変数しかデータがなく、過去データを上手く定義・収集できないため、機械学習のような AI の仕組みを使っても精度が出ない場合があるためです。
中長期予測を典型的な例で説明すると「実担当者が勘と経験(カンコツ)をベースに Excel 表を使って実施している予測」ということがよくあります。
現場では、同じ商品でも、各国独自の方法でばらばらに予測をしていたり、その予測をしている方しかできず、その人が異動されると本当に困る・続けられなかったり、長期予測は現場のカンコツでも全然当たっていなかったり、と言った様々な背景から、AI で需要予測を実施したいという背景があります。
このような予測は、世の中の変化に合わせて定期的に再学習を継続させることを前提に、多くの説明変数(数値/カテゴリ)”から特徴量を作り、AI に学習させて予測を行うことがポイントとなります。
信頼できる AI という観点で、予測誤差の理由把握は AI を進めるに当たって常に重要ですが、予測の改善という観点で、予測誤差の理由把握が非常に重要になります。
100%当たり続ける予測はありえないので、予測がある程度外れた場合、その改善には需要予測 AI が、その外れたときにどのような項目を重視して予測したかを認識して、改善に繋げていきましょう。確認すべき部分は、需要予測全体としての説明性ではなく、その予測を外したときの説明性(前者をグローバルな解釈性、後者をローカルな解釈性と言います)です。
次回に関して
次回後編
は、本コラムのサブタイトルに記載しました、需要予測 AI を利用することによって、データドリブンに関係者間で意志決定を実施して行きませんか?というお話しをさせていただきます。
執筆
AITC センター長
深谷 勇次
